非科班生转行大数据避坑指南,附详细学习路线与资源推荐
<股票配资网>非科班生转行大数据避坑指南,附详细学习路线与资源推荐
前言
本文针对非科班生转行大数据所遇到的问题,提出一些切实的建议,以免小伙伴在学习过程中走弯路。
我依据自己转行所走过的一些弯路,总结了我自己大数据学习的详细路线,推荐一些我看过的大数据课程以及技术书籍,帮助各位小伙伴做一个资源筛选。
我能够理解每一位即将转行和正在转行的小伙伴,你们可能焦虑自己是否能够学好这么多的大数据知识,也可能正在担心35岁后的自己该怎么办?
曾经的我,也曾陷入同样的焦虑和迷茫情绪。这些情绪完全是由于自己在学习过程中,你所期望的高度和自己目前所处的高度的落差所导致的,都是正常的情绪。
但是我觉得我们也不要过于担忧,因为未来总是不可预测的,谁也不知道35岁以后的我们会做什么,我们不要过早的杞人忧天,也不要过早的限制自己,我们现在所选择的工作,未来不一定就得干到老。
所以,当前我们应该要先沉淀自己,打造自己在未来的核心竞争力,先攒到自己的第一桶金才是王道,有资本了,就有更多的选择和更大的可能。
1大数据发展前景
我根据我国发布的《第十四个五年规划和2035年远景目标纲要》,带大家看看以下一个指标。
在创新驱动这个类别中,数字核心产业增加值占GDP比重要从2020年的7.8%,到2025年要增加到10%。这个概念大家可能还不是很敏感,跟着小林继续看下面另一张图。
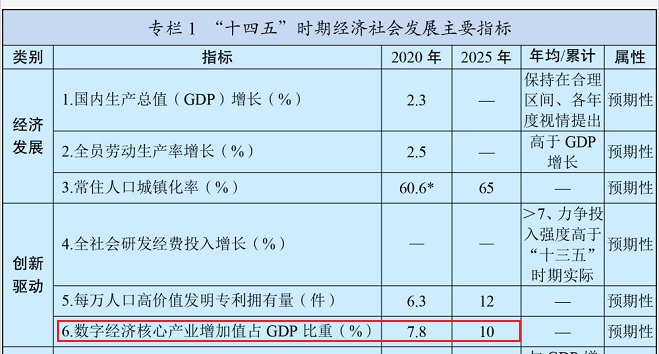
经济社会发展主要指标我国在大力发展的数字经济核心重点产业中,其中包括大数据领域,如下图所示。政府大力推动大数据领域技术发展创新,实现数字化转型,大数据在未来有较大的发展潜力!

数字经济重点产业2020年是我国5G的元年,国家在大力建设 5G 的基础设施。2021年,5G手机可能会逐渐增长,将会是大数据爆发的1年。5G网络所产生的数据速率:每秒 10G 的数据量,这会使得各个公司的数据量爆发式增长。
此外,我国第一批大数据专业在2017年开设,2021年第一批大数据专业学生才毕业。因此,大数据领域人才紧缺,需要大量的数据研发、数据分析以及数据挖掘工程师。
2学习路线总论
未来想在互联网发展,应该怎么学?就大数据方向来说,我个人认为主要有三个方面:
第一,计算机基础知识是不可或缺的,如果你拥有扎实的基础知识,在遇到问题时可以快速认识到问题的本质,从而解决问题。我至今在不断在加强自己计算机基础知识的学习;
第二,大数据框架的技术原理,对于重点框架要重视企业级调优以及源码的学习。
第三,项目实战。学习了大量的技术需要结合项目场景去应用,才能加深你对技术的理解。
大数据是一个进可攻、退可守的方向。
进可以往人工智能方向发展,但是需要非常扎实的数学知识。
我非常赞同我导师曾经跟我说的一句话:“任何问题,最终都会归咎于数学问题”!因此较好的数学能力可以支撑你不断的挑战新的问题!
退可以往大数据应用开发方向发展,但是需要丰富的框架使用和调优经验。
2.1计算机基础
推荐数学是考虑到一些小伙伴要进一步往 AI 方向发展,而数学是机器学习的基石。你只有拥有了这些底层基础,才能支撑你走得更远!
2.2大数据组件
整个大数据知识体系学习需要花较长的时间,大数据框架也比较多,下图是我自学大数据的技术栈。我是依据目标企业的招聘要求,选择以下技术栈学习,还有其它的框架,可以视情况而定,选择要不要学。
Java是基础工具,我个人是学完,重点对集合、多线程以及JVM进行深入学习,没有花时间学。如果你时间充裕,比如大二或者研一同学,可以深入学习,再进行后续的学习也行。
目前企业生产基本使用的是 Linux 系统,掌握 Linux 基本原理是未来必备技能。
是分步式系统基础架构,主要解决海量数据的存储和海量数据分析计算问题,包含HDFS,,Yarn 三个组件。其它框架在此不作介绍了。
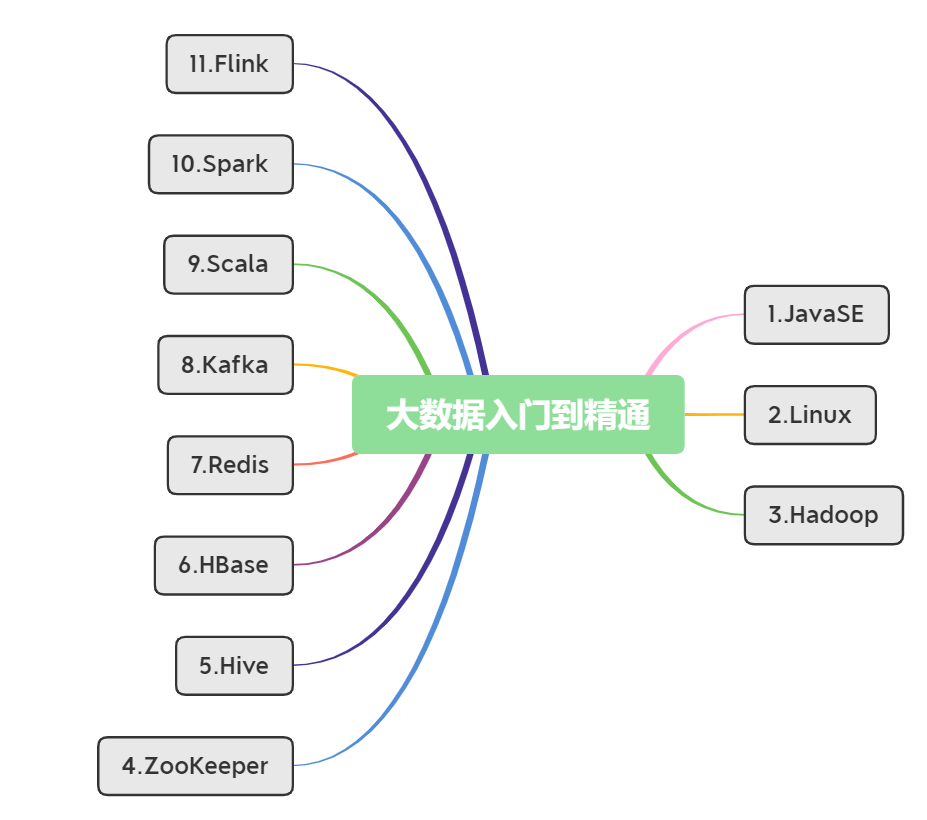
大数据重点技术栈针对一个技术框架如何学习大数据学习路线,可以参照我下面这个视频!我总结了框架学习要按照阶段去学,循序渐近,而不是一蹴而就,急功近利会导致你技术学的不够深入不说,更重要的是浪费了你的时间。
2.3项目实践
大部分非科班同学都会遇到的痛点,在学校没有实际的项目。但是找工作的时候,简历上至少需要2~3个项目非科班生转行大数据避坑指南,附详细学习路线与资源推荐,并且要有1~2个亮点项目。比如在某个项目中,你遇到什么困难,采用什么技术解决的?做了哪些优化?
关于项目这块,后面我有项目实战推荐!
3学习资料推荐
我自己作为一名非科班转型者,深知一份好的入门学习资料可以节约多少时间。因此,我对自己自学以来的历程,做了一下复盘,并且把我自己的学习路线以及自学的学习资料推荐给大家。
希望能够给转行的小伙伴们一点参考。主要包含了计算机基础知识、大数据框架学习、项目实战三个模块相关的入门视频和好的书籍推荐!
建议零基础同学先学习Java语言基础语法,一个月左右便可以把学完,后续找面经查漏补缺!
之后搭建Linux虚拟机平台,为后续大数据框架学习作准备。
因为我的时间比较紧急,不仅要完成导师布置的任务,还要挤出时间学习。所以,我的计算机基础知识是穿插在大数据框架学习中间,面试前重点刷了一些常见的面试题。以下是我刷的Java面试题博客链接。
最全 Java 面试总结: \.html
3.1基础
编程语言基础:Java基础是所有后续大数据学习的基石。我最开始是通过看书学习,看完后没有什么感觉,幸好之后找到了尚学堂高淇的300集,这个视频里把每一个知识点都讲的非常全面,也会有详细的案例。如果你是零基础,建议看视频入门,代码一定要自己敲一遍,切忌眼高手低!
高淇三百集:
Java 推荐《Java编程思想》,有在线中文版
此外,还有Scala语言,因为后续要学到 Spark、Flink等框架,这些框架采用Scala编程极为灵活,所以需要学习Scala的编程规范。关于Scala学习,推荐尚硅谷老师的视频。
尚硅谷Scala语言入门:
注意:在这个阶段,Scala 语言可以先不学,可以在学习 Spark 之前学习!
数据结构与算法:强烈推荐左神的视频大数据学习路线,他讲的内容基本上和企业面试相关,通俗易懂。我当时看的是一个在牛客网上讲视频:其中包括算法初级和进阶。在听这个视频前,最好去了解下基本的数据结构!可以从下面百度网盘中获取视频资料和课件!看完视频后,具备一定的基础了,可以把剑指offer刷完!
数据结构与算法视频链接:
提取码:3ojw
如果网盘链接失效,请添加我微信:,备注【左神算法】,我重新给你发一遍!
计算机网络与基础:我当时看的是B站方老师讲解的视频,讲的比较全面透彻,而且时间也不是很长,总共42节,每节平均40分钟左右,一周左右便可以看完,针对非科班同学特别友好!要留大把时间给后面技术框架学习,听完视频,可以去搜一搜相关的面经,可以查漏补缺。
方老师计算机网络链接:
操作系统:操作系统知识比较多涉及到的内容也比较细,如果你的时间充裕,且不着急面试找工作的话,你可以去B站搜索哈工大李治军老师的课程,老师会用Linux内核代码得视角帮助你理解操作系统得原理。
操作系统链接:
如果你时间紧急,想直接应对面试,这里给你分享一份总结好的操作系统重点面试知识!
请添加我微信:,备注【操作系统】,我给你发一份详细的操作系统面试知识!
数学理论基础:大数据与人工智能结合,那么数学基础是不可或缺的。但是,数学是学不完的,也没有几个人像数学专业的同学或者博士那样精通数学,所以大家要认识到,入门 AI 只要掌握数学中的基础知识就好,主要包含:高等数学、线性代数、概率论与数理统计三门课程。这里为大家整理了三篇简易的数学入门文章:
高等数学:
线性代数:
概率论与数理统计:
推荐笔记:《机器学习的数学基础》和《斯坦福大学机器学习的数学基础》
链接:
提取码:iihb
如链接失效,请加我微信:,备注【数学基础】
3.2大数据框架
Linux:无论你做的是后端还是大数据,Linux已经成为企业筛选人才的一个标准。我极力推荐观看尚硅谷韩顺平老师的Linux入门视频教程,清华大学的学霸,课程逻辑清晰,讲解透彻。
国内入门Linux课程几乎选择该门课程。这也是我学习印象最深刻的一门课,看完后,只能一句卧槽,居然还能讲的的这么清晰!

尚硅谷韩顺平Linux链接:
可以结合《Linux就该这么学》这本术一起学习,加深对 Linux 理解!
(重点):是大数据技术中最重要的框架之一,是学习大数据的第一课。
目前,已经从1.x版本发展到现在的3.x版本。一共包含3个组件:分别是最强的分步式文件系统HDFS,海量数据并行计算框架,流行的资源管理系统Yarn。
任何框架的学习,先搭建好环境,线上跑一个测试案例,之后再深入其原理。
HDFS有伪分布式、完全分步式以及高可用架构模型,重点了解HA架构模型以及各个角色的职责。
HDFS的架构模型主要包括以下角色:(、),,,ler(ZKFC),。
虽应用较少,但还是要了解其工作机制。
的核心思想、详细工作流程,机制也要重点掌握非科班生转行大数据避坑指南,附详细学习路线与资源推荐,面试会问。
Yarn资源管理系统不仅适用于计算框架,同时也会被用于Spark计算框架,所以它的工作机制也非常重要。
我推荐大家学习尚硅谷的教程,从原理到生产实践调优,再深入源码,非常透彻。
尚硅谷链接:
可以结合《权威指南》第四版学习。
如果对 源码感兴趣,可以参考《技术内幕》(董西成)和《.x HDFS源码剖析》这两本书。
:是一个分步式协调管理组件,主要的典型应用场景是数据发布/订阅、分步式协调/通知、集群管理等。
你可以结合《从Paxos到》这本书结合一起学,这本书不仅阐述了CAP理论,把的核心原理讲的很透。小白可以从下面这个视频入门。
尚硅谷链接:
注:视频仅作为初学者入门,要深入学习还需要看书和研究官方文档。
Hive:Hive 是一款开源数据仓库工具,它可以将结构型数据映射成一张表,但其底层使用的是,提供类SQL查询,一般称之为HQL。
初学者入门Hive,可以从视频开始,重点需要了解内部表与外部表的区别,以及分区分桶等。
如果你要深入学习其内部原理及调优,可以去读一读《Hive编程指南》和官方文档,对企业级的调优有详细的阐述。
尚硅谷Hive链接:
HBase:HBase是一个结构化数据的分步式存储系统,可扩展也支持海量数据存储的NoSQL数据库,是每一个大数据从业者应该要掌握的基本框架。重点要掌握其架构原理,各个角色职责,流程和流程。下面是入门 HBase 的视频教程。
尚硅谷HBase链接:
注:可以结合《HBase权威指南》和《HBase实战中文版》两本书,加深对 HBase 的理解。
Redis(重点!):Redis是一个开源的 key-value 存储系统,支持存储的 value 类型相对更多,并且支持各种不同方式的排序,为了保存效率,数据都是缓存在内存中。
该组件无论是后端还是大数据,都是必会的一个框架。我学习一个新技术,先是通过视频入门,之后再去看相关书籍和官方文档,深入理解技术细节。
Redis 推荐大家看尚硅谷周阳老师讲的,就是该课程有点老,很多新的特性可能无法了解。我贴出了两个Redis 课程入门学习链接:
尚硅谷周阳老师Redis链接:
2021最新入门到精通Redis链接:
推荐书籍:《Redis设计与实现》和《Redis 深度历险:核心原理与应用实践》
Kafka(重点!): 作为高吞吐量的分步式发布订阅消息系统,Kafka 可以处理消费者规模的网站中所有动作流数据。
这里建议:先了解 Kafka 是解决什么问题的而产生的,再了解其基本架构,最后深入理解核心实现原理。
下面是 Kafka 入门视频链接:
尚硅谷Kafka入门链接:
推荐书籍:首推《深入理解 Kafka:核心设计与实践原理》,想要深入了解 Kafka 源码的,你可以跟着《 Kafka 源码剖析》一起看,可以让你顿悟!
Spark(重点!重点!重点!):Spark 支持了 、SQL、、MLLib等应用。但相较于 中的 计算框架,Spark速度快10到100倍左右
另外,计算过程中,如果某一节点出现问题,事件重演的代价远低于 。Spark SQL 可以对结构化数据进行处理
Spark 主要用于实时流数据处理场景,支持多种数据源, 是 Spark 的基础抽象
Spark MLlib 提供了常见的机器学习功能的程序库, 主要用于图计算。下面是我为大家筛选的 Spark 入门学习链接,这个视频主要是基于Scala 2.12版本讲解,对最新的 .0作了详细的介绍,是一套小白入门学习的好资料。
从入门到精通链接:
注:学习 Spark 之前,一定要先学习 Scala 语言。在编程语言基础中,已经给出了 Scala 的详细学习推荐!
推荐书籍:《 Spark》、《深入理解Spark 核心思想与源码分析》
Flink(重点!重点!重点!):Flink 是一个分步式处理引擎,用于对无界和有界数据流进行状态计算。Flink 计算具有快速、灵巧、结果准确以及良好的容错性等一系列优点,被广泛用于各行各业的流式数据场景。
目前,国内形成以阿里为首的企业,腾讯,京东,滴滴,携程,美团等,都在使用 Flink框架。Flink 在大数据的流式计算占据着非常重要的地位,每一个大数据人都应该要掌握这门技术。
Flink 给大家推荐的是尚硅谷武老师的课,清华毕业的武老师把技术知识点剖析得非常透彻,该课程主要包含两个模块:Flink 理论基础和基于 Flink 得电商用户行为分析项目实战。
尚硅谷Flink链接:
推荐书籍:《Flink原理、实战与性能优化》
数据挖掘和机器学习这部分内容,我目前还没有学习,等后续我学完后,再整理这部分内容给大家作个参考。
3.3项目
关于项目,这是咱们非科班同学在面试时最薄弱的一环。在学校,你几乎很难去做一个实实在在的落地项目,因为基本接触不到相关的项目。
因此,我建议大家要提前计划实习,通过实习让自己获得项目经验。我是从研二上学期开始自学编程的,本科粗浅的学过一点 C++,算是有一点点基础。
当时,我一边帮导师做自己专业相关的课题项目,一边学习大数据技术。下图是我自学时做的部分笔记。
学习笔记如果你现在处在大二、研一这个阶段,你可以提前计划实习,在实习公司主动去了解一些相关的落地项目;但如果你即将面临找工作,并且各个技术栈还没有学完,你可以先把基础技术框架过一遍,然后参照我给你推荐的下面几个项目。
尚硅谷大数据电商数仓项目链接:
技术选型:++Hive+Flume+Sqoop+Kafka++Kylin+Spark
这个项目主要是讲解了数据仓库的架构模型,实现了数仓项目的闭环,从数据采集到数仓建模,再到数仓应用等。项目中还涉及到一些其它技术,中间可以穿插着学习。
在面试过程中,首先要把项目架构说清楚以及技术选型的原因,是否有其它替代方案;其次说明你在项目中碰到了什么问题,你用什么方法解决该问题的;最后要清晰的能表述出你负责的部分的代码逻辑。
虽然说,电商数仓项目比较普遍,但在没有项目的情况下,可以作为基础项目。
尚硅谷大数据实时处理()项目链接:
\_id\_from=333.788.b\.27
该项目基于对电商平台的用户行为以及订单业务,通过不同的指标和维度,进行实时的分析和计算。主要包括数据产生,数据传输,数据计算以及最终的数据可视化。
可以掌握实时计算的流程,还可以掌握大数据采集框架、高并发的分步式消息队列、基于内存的高吞吐的实时计算技术、以及海量存储毫秒级查询的数据库。
Flink实时项目:这个项目是我自己私藏的项目,你可以添加我的微信,给你发 Flink 项目资料。